���̃v���W�F�N�g�ͤ�����w�K���{�b�g�̊J����ڕW�Ƃ���Ɠ����ɂ��̊J����ʂ��Ĥ
�M�B�z�K�n��Ȃǒn��Y�Ƃ̊������⤐V�����Y�Ƃ̑n�o���ڎw���Ă��܂��
�{�y�[�W�̋L�q�͉��L�̉���L�������Ƃ�WEB�p�ɏC���������̂ł���F
�ؑ� ���C�{�� �a���C���� �d�M�F
�����w�K�V�X�e���̐v�w�j�C
�v���Ɛ���, Vol.38, No.10, pp.618--623 (1999), �v����������w��.
6 pages, postscript file, sice99.ps (1.31MB)
PDF file, sice99.pdf (148KB)
��P�́F �����w�K�̊T�v
1.1 �����w�K (Reinforcement Learning) �Ƃ�?
1.2 ����̎��_���猩�������w�K�̓���
1.3 ���p����҂ł��邱��
��Q�́F �����w�K�̓K�p��F���{�b�g�̕��s����l��
��R�́F �����w�K�̊�b���_
3.1 �}���R�t����ߒ�(Markov decision process: MDP)�Ƃ́H
3.2 MDP�̍œK���F������V�ɂ��]��
3.3 �}���R�t����ߒ�(MDP)�̊��ɂ����鋭���w�K(Q-learning)
��S�́F ���p���w���������_�ƋZ�p
4.1 �Z�~�}���R�t����ߒ�(SMDP)
4.2 �����ϑ��}���R�t����ߒ�(POMDP)
4.3 �A���ȏ�ԋ�Ԃւ̑Ή�
4.4 �A���ȍs����Ԃւ̑Ή�
4.5 �}���`�G�[�W�F���g�����ł̋����w�K
4.6 �����w�K�A���S���Y���̊K�w��
4.7 ���p�ɕK�v�Ȃ��̑��̋Z�p
��T�́F �����w�K�̉��p��
5.1 �Z�����[�ʐM�V�X�e���̎��g���т̓��I���肠��
5.2 �ɊǗ��E���Y���C���œK��
5.3 �|���U�q�̐U��グ���艻
5.4 ���̑��̉��p��
������
�Q�l����
��P�́F �����w�K�̊T�v
1.1 �����w�K (Reinforcement Learning) �Ƃ�?
�����w�K�Ƃ́C���s�����ʂ��Ċ��ɓK������w�K����̘g�g�ł���D
���t�t���w�K(Supervised learning)�Ƃ͈قȂ�C��ԓ��͂ɑ��鐳�����s��
�o�͂��I�Ɏ������t�����݂��Ȃ��D�����ɕ�V�Ƃ����X�J���[�̏���
�肪����Ɋw�K���邪�C��V�ɂ̓m�C�Y��x�ꂪ����D���̂��߁C
�s�������s��������̕�V���݂邾���ł́C�w�K��̂͂��̍s������������
�����ǂ����f�ł��Ȃ��Ƃ���������D
�����w�K�̘g�g��Fig.1�Ɏ����D
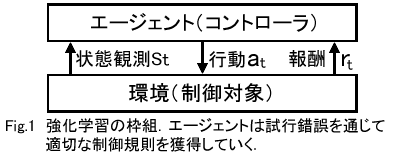
�w�K��́u�G�|�W�F���g�v�Ɛ���Ώہu���v�͈ȉ��̂��Ƃ���s���D
- �G�|�W�F���g�͎���t�ɂ����Ċ��̏�Ԋϑ�S(t)�ɉ����� �ӎu������s���C�s��a(t)���o��
- �G�|�W�F���g�̍s���ɂ��C����S(t+1)�֏�ԑJ�ڂ��C ���̑J�ڂɉ�������Vr(t)���G�|�W�F���g�֗^����D
- ����t��t+1�ɐi�߂ăX�e�b�v1�֖߂�D
�G�|�W�F���g�͗����ireturn: �ł��P���ȏꍇ�C��V�̑��v�j
�̍ő剻��ړI�Ƃ��āC��Ԋϑ�����s���o�͂ւ̃}�b�s���O�i����ipolicy�j
�ƌĂ��j���l������D
���ƃG�|�W�F���g�ɂ͈�ʂɉ��L�̐������z�肳���D
- �G�|�W�F���g�͗\�ߊ��Ɋւ���m���������Ȃ��D
- ���̏�ԑJ�ڂ͊m���I�D
- ��V�̗^�������͊m���I�D
- ��ԑJ�ڂ��J�Ԃ�����C����ƕ�V�ɂ��ǂ蒅���悤�ȁC �i���I�ȍs����K�v�Ƃ�����i��V�̒x��j�D
1.2 ����̎��_���猩�������w�K�̓���
�����w�K�����ڂ��W�߂闝�R�̈�́C �s�m�����̂�����������Ă���_�ɂ���D �����̎����E�̐�����ł́C�s�m�����̈����͖��ł���D ������̗��R�́C ��V�ɒx�ꂪ���݂��C���U�I�ȏ�ԑJ�ڂ��܂i���I�� ����K���̊l�����s���_�ɂ���D �v�҂��S�|����Ԃŕ�V��^����Ƃ����`�ŁC ���������^�X�N���G�|�W�F���g�Ɏw�����Ă����C �S�|���ւ̓��B���@�̓G�|�W�F���g�̎��s����w�K�ɂ���Ď����I�� �l�������D �܂� �v�҂��u�������ׂ����v���G�|�W�F���g�ɕ�V�Ƃ����`�� �w�����Ă����u�ǂ̂悤�Ɏ������邩�v���G�|�W�F���g���w�K�ɂ���� �����I�Ɋl������g�g�ƂȂ��Ă���D
1.3 ���p����҂ł��邱��
1.3.1 ����v���O���~���O�̎������E�ȗ͉�
���ɕs�m������v���s�\�Ȗ��m�̃p�����[�^�����݂���ƁC�^�X�N�̒B�����@ ��S�[���ւ̓��B���@�͐v�҂ɂƂ��Ď����ł͂Ȃ��D ����ă��{�b�g�փ^�X�N�𐋍s���邽�߂̐���K�����v���O�������邱�Ƃ͐v �҂ɂƂ��ďd�J���ł���D �Ƃ��낪�C �B�����ׂ��ڕW���V�ɂ���Ďw�����邱 �Ƃ͑O�L�ɔ�ׂ�Ηy���ɊȒP�ł���D ���̂��߁C�^�X�N���s�̂��߂̃v���O���~���O�������w�K�Ŏ��������邱�Ƃɂ� ��C�v�҂̕��S�y�������҂ł���D �\���ɗD�ꂽ���\���������w�K�G�[�W�F���g���R���g���[���Ƃ��ĂP�����J �����Ă����C���Ƃ̓��{�b�g�̖ړI�ɉ����ĕ�V�̗^����������v�҂��ݒ� ���邾���ŁC�������ނ̃��{�b�g������@��̃R���g���[���ɂ���Ď� ���I�Ɋl���ł���D
1.3.2 �n���h�R�[�f�B���O�����D�ꂽ��
���s�����ʂ��Ċw�K���邽�߁C �l�Ԃ̃G�L�X�p�[�g�������������D�ꂽ��������\��������D ���ɕs�m�����i���C��K�^�C�U���C�덷�Ȃǁj�� �v��������Ȗ��m�p�����[�^�������ꍇ�C�l�Ԃ̏펯�ł͑Ώ�����Ȃ����Ƃ� �\�z����C�����w�K�̌��ʂ����҂ł���D �G�L�X�p�[�g�̐���K�����w�K������Ԃɐݒ肵�āC��������P����ꍇ �ƁC�S���̃[������w�K���J�n���C�v�҂ɂƂ��Ă͈ӊO�ȐV�������� ��������ꍇ�Ƃ��l������D
1.3.3 �������Ƒz��O�̊��ω��ւ̑Ή�
�@�B�̏�Ȃǂ̋}���ȕω���v�����g�̌o�N�ω��̂悤�Ȋɖ��ȕω��ȂǁC �\�ߎ��Ԃ�z�肵�ăv���O���~���O���Ă������Ƃ�����Ȋ��̕ω��ɑ� ���Ă������I�ɒǏ]���邱�Ƃ����҂ł���D ���ɉF����C��ȂǁC�ʐM�������I�ɍ���ȏꍇ��C �ʐM�l�b�g���[�N�̐���̂悤�Ɍ��ۂ̃_�C�i�~�N�X���l�ԂɂƂ��đ������� �ꍇ�ɂ����āC�����w�K�̎����I�ȓK���\�͂����ɈЗ͂�����D
��Q�́F �����w�K�̓K�p��F���{�b�g�̕��s����l��
�O�͂Ő������������w�K�̗��_�ɂ��āC��̗�������Đ�������D���{�b�g�̕��s����l���̃y�[�W��
��R�́F �����w�K�̊�b���_
�����w�K���_�ł́C���̃_�C�i�~�N�X�� �}���R�t����ߒ�(Markov decision process: MDP)�ɂ���ă��f�������C �A���S���Y���̉�͂��s���̂���ʓI�ł���D �ȉ��C�����w�K�̊�b���_�ɂ��ĊȒP�ɐ�������D3.1 �}���R�t����ߒ�(Markov decision process: MDP)�Ƃ́H
���̃_�C�i�~�N�X���ȉ��̂悤�Ƀ��f���������̂�MDP�ł���D
���̂Ƃ肤���Ԃ̏W���� S = �o s 1 , s 2 , �c , s n �p�C
�G�[�W�F���g���Ƃ肤��s���̏W����
A = �o a 1 , a 2 , �c , a l �p
�ƕ\���D
�����̂����� s �� S �ɂ����āC�G�[�W�F���g������s�� a ��
���s����ƁC���͊m���I�ɏ�� s' �� S �֑J�ڂ���D
���̑J�ڊm���� Pr�o st+1 = s' | st = s, at = a �p=
Pa(s,s') �ɂ��\���D
���̂Ƃ�������G�[�W�F���g�֕�V r ���m���I�ɗ^�����邪�C
���̊��Ғl��
E�o rt | st = s, at = a, st+1 = s' �p=
Ra(s,s') �ɂ��\���D
�G�[�W�F���g�̊e�����ɂ�����ӎu����́C
�������(s, a) = Pr{ at = a | st = s},
�i�������S���s,�S�s��a�ɂ����Ē�`�����j�ɂ���ĕ\�����D
����͒P�ɐ���� �Ƃ��Ă��D
���}���R�t���F ���s'�ւ̑J�ڂ��C ���̂Ƃ��̏��s�ƍs��a�ɂ݈̂ˑ����C ����ȑO�̏�Ԃ�s���ɂ͊W�Ȃ����ƁD
���G���S�|�g���F �C�ӂ̏��s����X�^�|�g���C�������Ԍo�߂�����̏�ԕ��z�m���� �ŏ��̏�ԂƂ͖��W�ɂȂ邱�ƁD
3.2 MDP�̍œK���F������V�ɂ��]��
���鎞�ԃX�e�b�v�Ŏ��s�����s�����C
���̌�̕�V�l���ɂǂ̒��x�v�������̂���]�����邽�߁C
���̌㓾�����V�̎��n����l����D
��V�̎��n��]���͗���(return)�ƌĂ��D
�G�[�W�F���g�̊w�K�ڕW�́C�������ő剻���邱�ƁC
���邢�͂��̂悤�Ȑ�������߂邱�Ƃł���D
�����w�K�ł́C������V���v�ɂ��]���𗘓��Ƃ��ėp����ꍇ�������D
����́C���Ԃ̌o�߂ƂƂ��ɕ�V�������� �� (0 �� �� < 1)�Ŋ������č��v����D
���鎞�� t�ɂ������ԁC���邢�͂��̂Ƃ����s�����s���̗��� V t
���ȉ��Œ�`����D
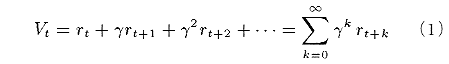
������ rt �͎��� t �ɂ������V�ł���D
���� Vt �̊��Ғl�́C1 �X�e�b�v������ ( 1 - �� ) �̊m���Œ�~����G�[�W�F
���g�ɂ���ē������V���v�̊��Ғl�Ɠ����ł���D
�����̕�V�����������R�͈ȉ��ɂ��D
- �����ł́C���Ԃ̌o�߂ƂƂ��Ɋ����ω�������C �G�[�W�F���g���̏ᓙ�Œ�~����\�������邽�߁C ���n���̑S�Ă̕�V���d�݂ōl������̂͑Ó��ł͂Ȃ��D ������X�N���l������K�v������D
- �������Ԏ��n��̗�����L���̒l�Ƃ��Ĉ������߁D
���œK��State-Value���F�S�Ă̏�� s �ɂ�����
V��(s) �� V��'(s) �ƂȂ�Ƃ��C
���� �� �� ��' ���D��Ă���Ƃ����D
�}���R�t����ߒ��ł́C���̂ǂ�Ȑ�������D�ꂽ�C���邢�͓����Ȑ����Ȃ��Ƃ�1���݂���D
����� �œK���� ��* �Ƃ����D
�œK����͕������݂��邱�Ƃ����邪�C�S�Ă̍œK����͗B���State-Value�������L����D
����͍œK��State-Value�� V* �ƌĂ�C�ȉ��̂悤�ɒ�`�����D
V*(s) = max�� V��(s), for all s �� S.
���œK��Action-Value���F�œK�Ȑ���͂܂��C
�ȉ��Ɏ����B���Action-Value�������L����D
Q*(s,a) = max �� Q��(s,a) �C
for all s �� S and a �� A.
Q*(s,a) ��Q�l�ƌĂ�C��� s �ōs�� a ��I����C�����ƍœK�����
�Ƃ�Â���Ƃ��̗����̊��Ғl��\���D
Q*(s,a) ���^����ꂽ�ꍇ�C
��� s �ɂ����čő��Q�l�����s�� a ���œK�ȍs���ł���D
3.3 �}���R�t����ߒ�(MDP)�̊��ɂ����鋭���w�K
�}���R�t����ߒ��̊����ł̋����w�K���́C�ȉ��̂悤�ɒ莮�������D- �G�[�W�F���g�͊��̏�ԑJ�ڊm�� Pa(s,s') ���V�̗^������ Ra(s,s') �ɂ��Ă̒m����\�ߎ����Ȃ�
- �G�[�W�F���g�͊��Ƃ̎��s����I�ȑ��ݍ�p���J��Ԃ��āC�œK�Ȑ�����w�K����D
��Q-learning�̏����葱���F S �~ A �̃G���g��������2�����z��ϐ�Q(s,a)
��p�ӂ��C�ȉ��̂悤�Ɋ��Ƃ̃C���^���N�V�����ɉ����ĕϐ����C������B

Q-learning�̏�����}���������摜(Qlearning.jpg 88KB)
max a' Q( s',a') �́C���s'�ɂ����čő��Q�l�����s����Q�l���Ӗ�����D
{kind=link}
�� Q-learning�̎����藝 [Watkins92]�F
�G�[�W�F���g�̍s���I���ɂ����āC�S�Ă̍s�����\���ȉI�����C
���w�K������ �� t = 0 �� ��(t) �� ��
���� �� t = 0 �� ��(t) 2 < ��
�������� t �̊��ƂȂ��Ă���Ƃ��C
Q-learning�̃A���S���Y���œ���Q�l�͊m��1�ōœK��Q�l�Ɏ�������(�T����)�D
���������̓G���S�[�g����L���闣�U�L���}���R�t����ߒ��ł��邱�Ƃ����肷��D
���̑��C��͂ɂ��Ă͕��� [Bertsekas96]���Q�ƁD
�� �s���I����@(�T���헪)�F
��L�̎����藝�́C�S�Ă̍s�����\���ȉI�������������
�s���I����@(�T���헪)�ɂ͈ˑ������ɐ��藧�D
����čs���I���̓����_���ł��悢�D
�������C�����w�K�ł͂܂�Q�l���������Ă��Ȃ��w�K�̓r���ɂ����Ă��Ȃ�ׂ�����
�̕�V��悤�ȍs���I�������߂��邱�Ƃ������D
�w�K�ɉ����ď��X�ɋ��������P���Ă����悤�ȍs���I����@�Ƃ��āC�ȉ��̕��@����\�I�ł���D
- ��-greedy�I���F �� �̊m���Ń����_���C����ȊO�͍ő��Q�l�����s����I���D
semi-uniform policy �ƌĂ��ꍇ������ - �{���c�}���I���F exp(Q(s,a)/T)�ɔ�Ⴕ�������ōs���I���C ������T�͎��ԂƂƂ��Ƀ[���ɋߕt���C
��S�́F ���p���w���������_�ƋZ�p
�O�͂�MDP�ɂ������f�����Ƌ����w�K�@�́C �A���S���Y�����P���Ȋ��ɍœK���ւ̎������ۏႳ���Ƃ����Ӗ��ŋ��͂����C ���̂܂܉��p����ɂ͖�肪�����D ���p������ɂ́C�K�p������̐����ɉ����Ċ��̃��f������A���S���Y���� �H�v����K�v������D �ȉ��ɂ��������Љ��D4.1 �Z�~�}���R�t����ߒ�(SMDP)
�l�b�g���[�N�̃��[�e�B���O��T�[�r�X�C�ɊǗ����ȂǁC�҂��s�������
���p���ł́C�ӎu����̎��ԊԊu�����ł͂Ȃ��C�����_���ɂȂ�D
�T�b�J�[���{�b�g�̂悤�ɒn�ʂ��������郍�{�b�g�ł́C
��莞�ԊԊu�ŕp�ɂɈӎu���肷��ƁC�w�K�������ꏊ���s�����藈�����
�J��Ԃ�����Ŋw�K���i�܂Ȃ����߁C����s����I���������Ԋϑ���
�ω����݂���܂ŐV���Ȉӎu��������Ȃ��Ȃǂ̕��@���Ƃ���[Asada97]�D
�����̖��ł́C�C�x���g�h���u���Ȉӎu�����C
�܂��ӎu����̎��ԊԊu���C�ӂȏꍇ�ɑΉ�����
�����w�K�����߂���D
���̂悤�Ȋ��̐������f���Ƃ��ăZ�~�}���R�t����ߒ�(SMDP)������D
�ȉ���SMDP���֑Ή�����Q-learning�A���S���Y���mBradtke94�n�mParr98�n�������D

�{�A���S���Y�����ʏ��Q-learning�A���S���Y���Ɠ��l�����_�I���������D
�T���헪�����l�D
4.2 �����ϑ��}���R�t����ߒ�(POMDP)
MDP�̊��ł́C�G�[�W�F���g�ɂ����̏�Ԋϑ��͊��S�ł��邱�Ƃ����肳 ��Ă���D �����������ł́C�m�C�Y��Z���T�̔\�͂��s�\���Ȃ��߁C��Ԋϑ��ɕs�m���� ��s���S�������݂��邱�Ƃ������D �����ϑ��}���R�t����ߒ�(POMDP)�mLovejoy91�n�́CMDP�̃��f�����g�����C �G�[�W�F���g�̏�Ԋϑ��ɕs�m������t�������������f���ł���C ��L�̂悤�Ȏ��������f�������ĉ�͂����ŗL�p�Ȓm����^����D POMDP�̊��ɑΉ����������w�K�@�́C�������̃A�v���[�`�ɕ��ނł��� �mKimura97c�n�F
- �G�[�W�F���g�����ŁC���̏�ԑJ�ڂ𐄒�^�\��������@(���f���x�[�X�� ��������ԕ\��)�C
- �L�����̉ߋ��̏�Ԃ�s���̗�����p����������ԕ\���C
- �m���I�Ȑ����p������@�C
4.3 �A���ȏ�ԋ�Ԃւ̑Ή�
�A���ȋ�Ԃɂ����鋭���w�K�̐����pOHP���������ł̓R���g���[���̏�ԓ��͂��A���l�̃x�N�g���ŗ^������ꍇ������ ���Ȃ��D�ʏ��Q-learning�A���S���Y���̌`���ɍ��킹�āC�A���l�̏�ԓ��� ��K�X���U������̂����ʂ����C��ԓ��̓x�N�g���̎��������傫���Ɓu������ ��(Curse of dimensionality)�v�ƌĂ���ԋ�Ԃ̔����������D
�A���ȏ�ԋ�Ԃł́C�e��ԊԂɈʑ��\��(�܂��ԊԂ̋������`�ł���) �����D�����I�ɋ߂���Ԃł�Q�l���߂��l�������C�Q�̏�Ԃ̒��Ԃ������ ���݂����Ԃ�Q�l�͂����Q��Q�l�̒��Ԃ��炢�̒l�������Ƃ������D �����ŁC�A���ȏ�ԋ�Ԃ��������w�K���ł́C Q-learning�ɂ�����Q�l��Value�̕\���Ɋ��ߎ���p���邱�Ƃ������D ���ߎ���p����ƁC�w�K�������ɂȂ�����C ���܂Ōo���������Ƃ̂Ȃ���Ԃɑ������Ă��C������Ԃł̌o�������� �K�ȍs���I�����ł���Ȃǂ̃����b�g������D ��\�I�Ȋ��ߎ��@�Ƃ��āCtile coding(CMAC)�C�j���[�����l�b�g�C�t�@�W�B�C �������Œ肵��radial-basis-function network�Cnearest neighbor�C locally weighted linear regression�Ȃǂ���Ă���Ă���mSutton98�n�D ��L�̊��ߎ��͑��w�j���[�����l�b�g�������Đ��`�A�[�L�e�N�`���ƌĂ��D ����́C�����ԓ��� s ���^����ꂽ�Ƃ��CValue���ߎ����邽�߂ɂ܂� s �� K ���������x�N�g�� ��(s) �� RK�Ƀ}�b�s���O���C ���� K �����̃p�����[�^�x�N�g�� W �Ƃ̐��`�a�ɂ�� V(s) = ��(s) �E W �̂悤�ɕ\�����̂ł���(Q�l�����l)�D ���`�A�[�L�e�N�`����p�����ꍇ�C����������ōœK�l�ւ̎������ۏ� �����mTsitsiklis97�n�D
���̑��C��ԋ�Ԃ�K���I�ɕ������Ă������@�mAsada97�n�mMoore95�n �Ȃǂ���Ă���Ă���D
4.4 �A���ȍs����Ԃւ̑Ή�
�A���ȋ�Ԃɂ����鋭���w�K�̐����pOHP���������ł͘A���l�̏�ԓ��͂Ɠ��l�C�A���l�̍s���o�͂����߂��邱�Ƃ������D �s����Ԃ𗣎U������̂����ʂ����C���܂�e�����U������ƍׂ₩�Ȑ��䂪�� ���Ȃ��Ƃ�����肪������D���Ƃ����ė��U�����ׂ�������ƒT����Ԃ����債�C �ʏ�̗��UMDP�ɂ�����Q-learning�Ƃ��̍s���I����@�ł́C �Ȃ��Ȃ��w�K���i�܂Ȃ��Ȃ����p�I�ƂȂ�D
�������̘A�����-�s����Ԃɂ�����Q-learning���s�����߂̎������@�̈�Ƃ��āA �M�҂́u�����_���^�C�����O��Gibbs�T���v�����O��p���������w�K�v���Ă��C �������{�b�g�V�~�����[�^��Rod-In-Maze���CMulti-Joint Arm���֓K�p�����i2005.12.06�X�V�j�D �����_���^�C�����O�͐��`�A�[�L�e�N�`���̂P�ł��邪�C �O���b�h�^�C�����O��b�l�`�b�̂悤�ɋK���I�Ƀ^�C������ׂ�̂ł͂Ȃ��C ��Ԓ��Ƀ����_���Ƀ^�C����z�u������@�ł���D �s�v�c�Ȃ��ƂɁC�����̃^�C�����O���b�h��ɋK���������z�u��������A �����_���ɔz�u�����ق����y���ɗǂ��w�K���ʂƂȂ�B Gibbs�T���v�����O�Ƃ́C�������̍s����Ԃɂ�����Q-learning�̍s���I���̂��߂� �c���Q�l�̏W�v���s���đI���m�����s��Ȃ���Ȃ�Ȃ��������C �ߎ��v�Z�ɂ���Čy�����邽�߂ɗ��p�����m���T���v�����O�@�ł���D Gibbs�T���v�����O���̂́C �������m����ԂŌ����ǂ��T���v���邽�߂̈�ʓI���@�ł���D �����ł́C�v�Z�R�X�g��1������1���x�Ɍy���ł����D �ȉ��ɕ����������̂ŎQ�l�ɂ��ꂽ���D
- �ؑ� ���F
�����_���^�C�����O��p�������������-�s���̋����w�K
�v����������w�� �V�X�e���E���w�p�u����2005�u���_���W, pp.37--42 (2005).
�\�e�W���e 6 pages, PDF file, ssi2005_u.pdf (255KB)
�u���Ɏg�p����PowerPoint������PDF�t�@�C��, SSI2005_1128ppt.pdf (576KB)
- �ؑ� ���F
�����w�K�ɂ����鍂�������̍s����Ԃ̈����ɂ��� �|�n�b�V����Gibbs-Sampling��p�����s���I����@�̒��-�C
�v����������w�� ��32��m�\�V�X�e���V���|�W�E��, pp.399--404 (2005).
6 pages, PDF file, sice20050137.pdf (302KB)
Fuzzy���}�^Q-learning�mHoriuchi99�n�́C �t�@�W�B��p�������ߎ��ɂ���ĘA���l�̍s���Ɋւ���Q�l��\�����C �s���I�����ɂ́C�s����ԂԊu�ɋ�����������̓_�ɂ���Q�l�� �v�Z����D�����̗��U�I�ȃ|�C���g�ɂ�����Q�l��p���čs�������肷�邪�C �A���I�Ȓl�̍s����I�Ԃ悤�Ȋg�����[���b�g�I�����Ă��Ă���D
�s����Ԃ��A���I�ȏꍇ�́CQ-learning����
actor-critic �mSutton98�n�mKimura98�n��
�Ă����@�̂ق������т�����D
����͏�Ԃ�Value��]������critic�ƌĂ�镔���ƁC��Ԋϑ��ɉ�����
�m���I�ɍs���I�����s��actor�Ƃ����Q�̗v�f���\�������D
������actor�͍s���I���̊m�����ł��镨�ł���悢�D�A���l�̍s��
�ł���Cactor�̊m���I����́C��ԓ��͂ɉ����Ē��S�l�ƕ��U���ω���
�鐳�K���z�Ƃ�����@������D�ȉ��Ɏ����Ƃ���C
�s����I���������ʁC�悢��Ԃ֑J�ڂ����Ȃ�I�������s������������D
���K���z��actor�̏ꍇ�ɂ����čs������������ɂ́C
���s�����s���֕��z�̒��S�l���ߕt���C���s�����s�����W�����̓����Ȃ�C
���K���z�̍L��������߁C�O���Ȃ�L����悤���߂���悢�̂ŁC
�����͋ɂ߂ĊȒP�ł���D
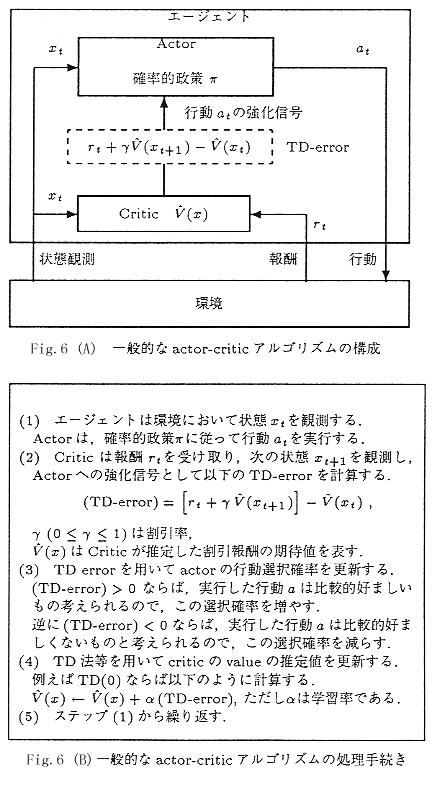
Actor-Critic�̏�����}���������摜(ActorCritic.jpg 71KB)
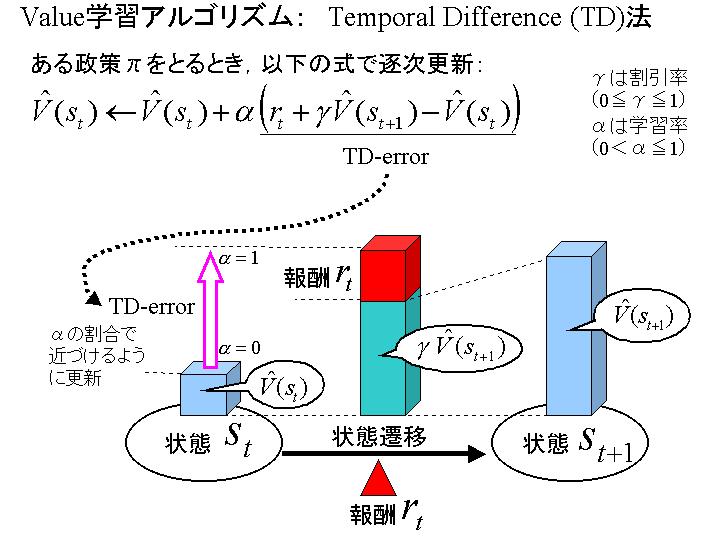
Critic�̏���(TD�@)��}�������������iPowerPoint2000�ɂč쐬�j
�E Critic�̏���(TD�@)��}���������摜(TD_method.jpg 75KB)
�E TD�@��value���w�K���Ă����l�q��}���������摜(TDExample.jpg 71KB)
{kind=link}
{kind=link}
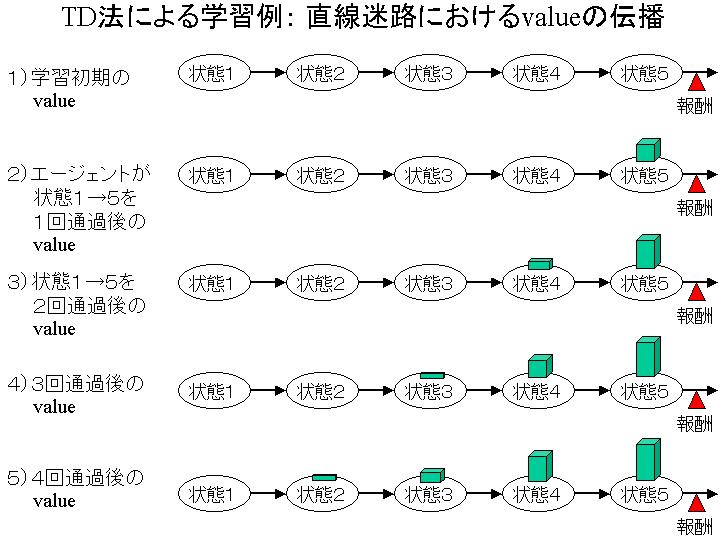{kind=link}
4.5 �}���`�G�[�W�F���g�����ł̋����w�K
���x�ɕ��G�C���剻�����V�X�e���ł́C ������x�̋@�\�P�ʂ��ƂɎ����I�Ȓm�I���f�����������C �������݂��ɋ��������鎩�����U�V�X�e���ɂ��Ǘ������߂��Ă���D ����͈ȉ���2�̗��R������D
- ���G����ȃV�X�e���S�Ă��W���Ǘ����邱�Ƃ́C �V�X�e�����̈ꕔ�ɔ��������̏�ɑ��ĐƂ��C �����̕ω��ɏ_��ɑΉ����g�����邱�Ƃ�����C ����\�t�g�E�G�A���쐬���邽�߂ɖc��ȘJ�͂�v����Ȃ� ��肪�����D
- �ғ����Ă���V�X�e���@�\�P�ʂ������Ât������悤�� �ʂ̎����I�ȃV�X�e���������邱�Ƃ��J��Ԃ������ɁC ���R�����I�Ɏ������U�V�X�e�����\�z����Ă��܂��D
4.6 �����w�K�A���S���Y���̊K�w��
�K�w�I�����w�K(Hierarchical RL)�́C��K�͂Ȗ������ĉ����Ƃ����Ӗ� �ɂ����ă}���`�G�[�W�F���g�Ɨގ����Ă���C �l�X�ȕ��@����Ă���Ă���mParr98�n�mSchneider99�n�mWang99�n�D �}���`�G�[�W�F���g�ƈقȂ�̂́C��ʊK�w�����ʊK�w(�T�u�^�X�N)�̒m���� �ė��p�܂��͋��L����_�ƁC ���ʊK�w�ł̕����ϑ�������ʊK�w�ŃJ�o�[�ł���_�ł���D
4.7 ���p�ɕK�v�Ȃ��̑��̋Z�p
�摜���͂Ȃǖc��ȃZ���T����̏��ǂ̂悤�ɂ��ď�ԕ\�������邩 �ɂ��ẮC�����w�K�Ɍ��炸AI�ɂ������{�I�ȉۑ�ł���mAsada97�n�D �܂��C�l�X�ȃ^�X�N�������ǂ��w�K���邽�߂ɂ́C���̏�ԑJ�ڂɊւ���m�� ��~���ă^�X�N���ɋ��L�^�ė��p���邱�Ƃ����ʓI�ƍl������D ����̓��f���x�[�X��@�ƌĂ�C �����̎�@����������Ă���mKaelbling96�n�mSutton98�n�D ���̑��C��V�̊��Ғl�ő剻�����ł͂Ȃ����X�N�ŏ����╡���]���K�͂Ȃǂ� ��������Ă���D
��T�́F �����w�K�̉��p��
�ȉ����p����Љ�C�O�ɏЉ�����_�Ƃ̊W�������D5.1 �Z�����[�ʐM�V�X�e���̎��g���т̓��I���肠��
������PHS�̂悤�ȒʐM�V�X�e���ł́C �T�[�r�X�n����Z���ƌĂ��n��ɕ������C�e�Z�����ł͊e�ʘb�҂� ���ꂼ��قȂ���g���т��g�����C�ߐڂ���Z���ł͓���̎��g���т� �g���Ȃ��Ƃ���������D����ꂽ�`�����l���ʼn\�Ȓʘb�����ő�ƂȂ� �悤�Ɏ��g���������Ă邱�Ƃ��v�������D �ʘb�T�[�r�X�v����ؒf�̔����͊m���I�ŁC�����̕p�x�̓Z�����ɈقȂ��C ���I�ɕϓ����邽�߁C��K�͂ɂȂ�Ɩ�肪�ɂ߂ĕ��G�ɂȂ�D Singh��́CSMDP�̋����w�K�Ɋ�Â����@���Ă��C�w�K���Ԃ����قǂ����邱 �ƂȂ������̃q���[���X�e�B�N�X�����鐫�\��B������[Singh97]�D
5.2 �ɊǗ��E���Y���C���œK��
Fig7�Ɏ����悤�ɁC�����̉��H�@�B��ɘA�����č\�����ꂽ
���Y���C���ɂ����āC�ɂ��ŏ��������i�̎��v�����悤�ȍœK�Ȑ���
���w�K������ł���D
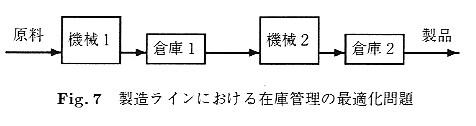
�e�@�B�̉����ɂ͑q��(buffer)���ݒu����C�@�B�̌̏ᒆ���邢�̓����e�i���X
���̐��i���v�ɑΉ����邱�ƂőS�̗̂���ɗ^����e�������Ȃ�����D
�e�@�B�͉^�p���Ԃ̑����ƂƂ��Ɍ̏Ⴊ�������₷���Ȃ�C
�̏Ⴗ��ƏC�����K�v�ł���D�R�X�g�̂�����C����������C
�ɕs���ɂ�郉�C����~������C���ɂ��R�X�g��������̂łȂ�ׂ��ŏ�
���̍ɂƂȂ�悤�ɁC�^�p���Ԃ�ɂ̗ʂɉ�����
�@�B�̉ғ��^�A�C�h�����O�^�����e�i���X�̃^�C�~���O�𐧌䂵�Ȃ���Ȃ�Ȃ��D
���̖���SMDP�Ƃ��ă��f�����ł��邪�C���C���S�̂�P��̃G�[�W�F���g��
�w�K����Ɩ��̃T�C�Y���������邽�߁C�e�@�B���ɃG�[�W�F���g�����蓖�Ă�
�}���`�G�[�W�F���g�V�X�e�����p��������[Wang99]�D
�g���^�̃J���o���������Ɣ�r���C�D�ꂽ����K�����l�������Ƃ̕�����D
����͋����w�K����ԑJ�ڂɕs�m�������܂݁C�S�̂̐��\���ő剻������ɂ�����
���͂Ȏ�@�ł��邱�Ƃ������Ă���
5.3 �|���U�q�̐U��グ���艻
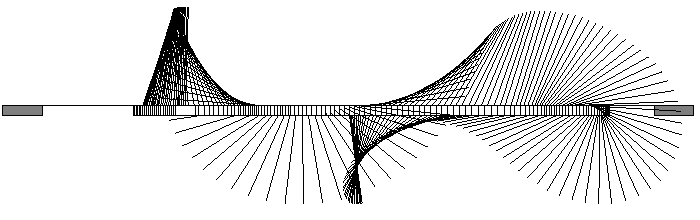
Fig.8: �|���U�q�̐U��グ���艻�̓����
�K�w����actor-critic�Ɋ�Â��A���l�s����g�ݍ��킹�邱�ƂŁC
Fig8�Ɏ����|���U�q�̐U��グ���艻���[������w�K����
�Ⴊ����Ă���[Kimura99c]�D
����̏����l�����t���^���C�����w�K�ɂ���Đ���̉��P���s�����Ƃɂ��
���₩�Ɋw�K������@����Ă���Ă���[Doya96]�D
5.4 ���̑��̉��p��
�G���x�[�^�Q����CJob-Shop�X�P�W���[�����O�C �o�b�N�M��������`�F�X�Ȃǂ̃Q�[���ւ̓K�p�Ⴊ����[Sutton98]�D �ߔN�ł͓d�͖Ԃ̕��U�w�K����[Schneider99]�� �C���^�[�l�b�g�o�i�[�̃X�P�W���[�����O�ւ̓K�p[Abe99]������Ă� ��D
������
�{�e�ł͋����w�K�������̖��֓K�p���邱�Ƃɏd�_��u���C ���ɍ��킹���A���S���Y���ɂ��ďЉ���D �������C�����ł͋����w�K�ŕK�v�ȁu���s����v��������Ȃ��ꍇ�������C ���{�b�g�̊w�K�ł͖����ȓ�����l������O�ɉ��Ă��܂��Ȃǖ��������D ���̂��߁C�����w�K�̉��p�ɑ��Ĕᔻ�I�Ȉӌ������邱�Ƃ������ł��邪�C ���t�t���w�K�Ƃ̑g�ݍ��킹�Ȃǂɂ���ĉ�������Ă������̂Ɗ��҂����D ����ɍ���C �����w�K�̎g�p��O��Ƃ����n�[�h�E�G�A�v���Ȃ����C �\�t�g�ƃn�[�h����̂ƂȂ����A�[�L�e�N�`���ɂ��C �����w�K�̃|�e���V�������\���ɐ������� ���܂łɂȂ��V�������i��T�[�r�X���o������\��������D
�Q�l����
- [Abe99] Abe, N. & Nakamura, A.:
Learning to Optimally Schedule Internet Banner Advertisements,
Proc. of 16th International Conference on Machine Learning, pp.12--21 (1999). - [Asada97] ��c ���F
�����w�K�̎����{�b�g�ւ̉��p�Ƃ��̉ۑ�C
�l�H�m�\�w�, Vol.12, No.6, pp.831--836 (1997). - [Bertsekas96] Bertsekas, D.P. & Tsitsiklis, J. N.:
Neuro-Dynamic Programming, Athena Scientific (1996). - [Bradtke94] Bradtke, S. J. and Duff, M. O.:
Reinforcement Learning Method for Continuous-Time Markov Decision Problems,
Advances in Neural Information Processing Systems 7, pp. 393--400 (1994). - [Doya96] Doya, K. :
Efficient Nonlinear Control with Actor-Tutor Architecture,
Advances in Neural Information Processing Systems 9, pp. 1012--1018 (1996). - [Horiuchi99] �x�� ���C���� ���T�C�Ј� �C�C���� �N�v�F
�A���l���o�͂������t�@�W�B���}�^Q-learning�̒�āC
�v����������w��_���W, Vol.35, No.2, pp.271--279 (1999). - [Hu98] Hu, J. & Wellman, M. P.:
Multiagent Reinforcement Learning: Teoretical Framework and an Algorithm,
Proceedings of the 15th International Conference on Machine Learning, pp. 242--250 (1998). - [Kaelbling96] Kaelbling, L. P., Littman, M. L. and Moore, A. W.:
Reinforcement Learning: A Survey,
Journal of Artificial Intelligence Research, Vol. 4, pp. 237--277 (1996). - [Kimura96] �ؑ� ���C�R�� ��K�C���� �d�M:
�����ϑ��}���R�t����ߒ����ł̋����w�K�F�m���I�X�Ζ@�ɂ��ڋ߁C
�l�H�m�\�w�, Vol.11, No.5, pp.761--768 (1996). - [Kimura97c] �ؑ� ���CKaelbling, L. P.:
�����ϑ��}���R�t����ߒ����ł̋����w�K�C
�l�H�m�\�w�, Vol.12, No.6, pp.822--830 (1997). - [Kimura98] Kimura, H. & Kobayashi, S.:
An analysis of actor/critic algorithms using eligibility traces: reinforcement learning with imperfect value function,
Proc. of 15th International Conference on Machine Learning, pp.278--286 (1998). - [Kimura99b] �ؑ� ���C���� �d�M�F
�m���I�X�Ζ@��p���������w�K�ƃ��{�b�g�ւ̓K�p�C
�d�C�w��C�d�q�E���E�V�X�e�����厏, Vol.119, No.8, pp.931--934 (����11�N). - [Kimura99c] Kimura, H. & Kobayashi, S.:
Efficient Non-Linear Control by Combining Q-learning with Local Linear Controllers,
Proceedings of the 16th International Conference on Machine Learning, pp.210--219 (1999). - [Littman94] Littman, M.:
Markov games as a framework for multi-agent reinforcement learning,
Proc. of 11th International Conference on Machine Learning, pp.157--163 (1994). - [Lovejoy91] Lovejoy, W. S.:
A Survey of Algorithmic Methods for Partially Observed Markov Decision Processes,
Annals of Operations Research 28, pp.47--65 (1991). - [Mikami97] �O�� ��F�F
�����w�K�̃}���`�G�[�W�F���g�n�ւ̉��p�C
�l�H�m�\�w�, Vol.12, No.6, pp.845--849 (1997). - [Teru97] �{�� �a���C���� �d�M�F
���U�}���R�t����ߒ����ł̋����w�K�C
�l�H�m�\�w�, Vol.12, No.6, pp.811--821 (1997). - [Teru99a] �{��a���C�r��K��C���яd�M:
Profit Sharing��p�����}���`�G�[�W�F���g�����w�K�ɂ������V�z���̗��_�I�l�@�C
�l�H�m�\�w�, Vol.14, No.6 (1999 �f�ڗ\��). - [Teru99] �{��a���C�ؑ� ���C���яd�M�F
Profit Sharing�Ɋ�Â������w�K�̗��_�Ɖ��p�C
�l�H�m�\�w�, Vol.14, No.5, pp.800--807 (1999). - [Moore95] Moore A. W. & Atkeson, C. G.:
The Parti-game Algorithm for Variable Resolution Reinforcement Learning in Multidimensional State-spaces,
Machine Learning 21, pp. 199--233 (1995). - [Ogasawara67] ���}�������C��{���i ���C�k�� �q�j ��:
���Ȋw�u��(�S62��)A�E5�E1 �}���R�t�ߒ��C�����o�� (1967). - [Parr98] Parr, R. & Russell, S.:
Reinforcement Learning with Hierarchies of Machines,
Advances in Neural Information Processing Systems 10, pp. 1043--1049 (1998). - [Schneider99] Schneider, J., Wong, W., Moore, A. & Riedmiller, M.:
Distributed Value Functions,
Proc. of 16th International Conference on Machine Learning, pp.371--378 (1999). - [Singh97] Singh, S. & Bertsekas, D.:
Reinforcement Learning for Dynamic Channel Allocation in Cellular Telephone Systems,
Advances in Neural Information Processing Systems 9, pp. 974--980 (1997). - [Sutton98] Sutton, R. S. & Barto, A.:
Reinforcement Learning: An Introduction,
A Bradford Book, The MIT Press (1998). - [Tsitsiklis97] Tsitsiklis, J. N., & Roy, B. V.:
An Analysis of Temporal-Difference Learning with Function Approximation,
IEEE Transactions on Automatic Control, Vol.42, No.5, pp. 674--690 (1997). - [Wang99] Wang, G. & Mahadevan, S.:
Hierarchical Optimization of Policy-Coupled Semi-Markov Decision Processes,
Proceedings of the 16th International Conference on Machine Learning, pp. 464--473 (1999). - [Watkins92] Watkins, C. J. C. H. and Dayan, P.:
Technical Note: Q-Learning,
Machine Learning 8, pp. 279--292 (1992).
�����w�K�̗�
�������̗�� �iJava�A�v���b�g�j�����w�K�������{�b�g�֓K�p
���\�_���ꗗ
�ؑ� ���̃z�[���y�[�W��